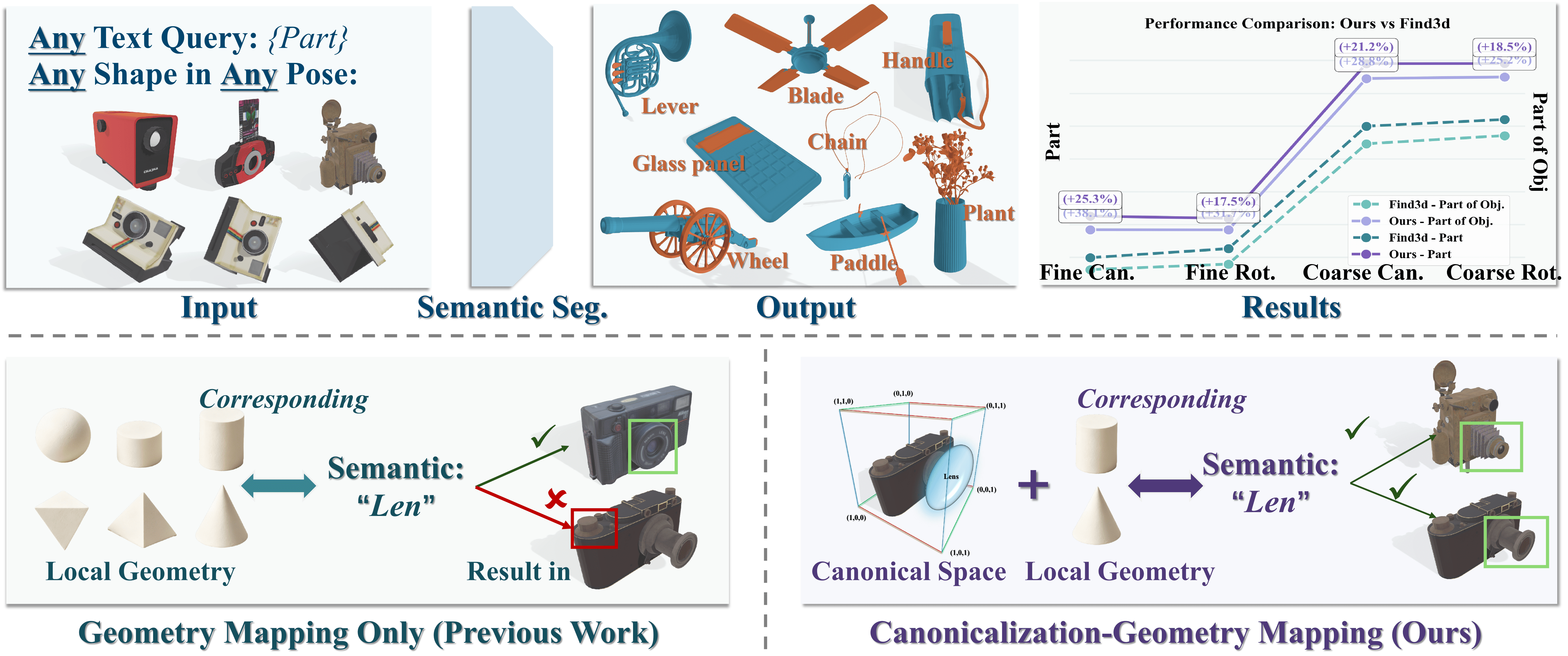
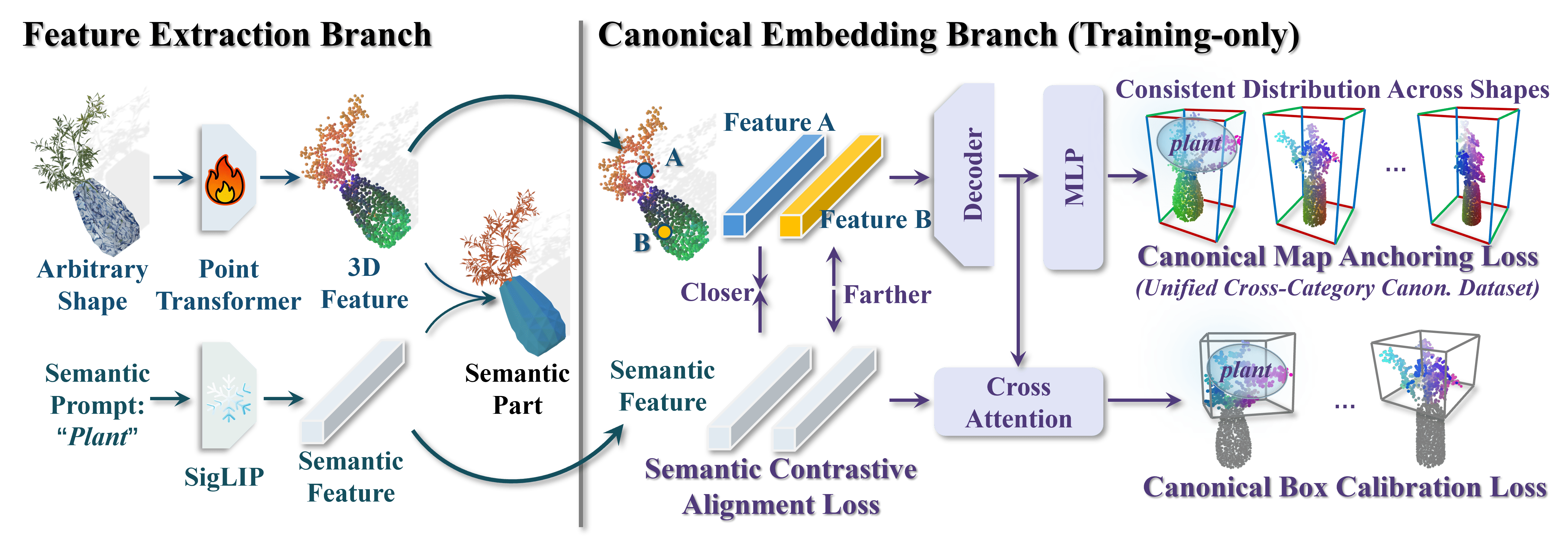
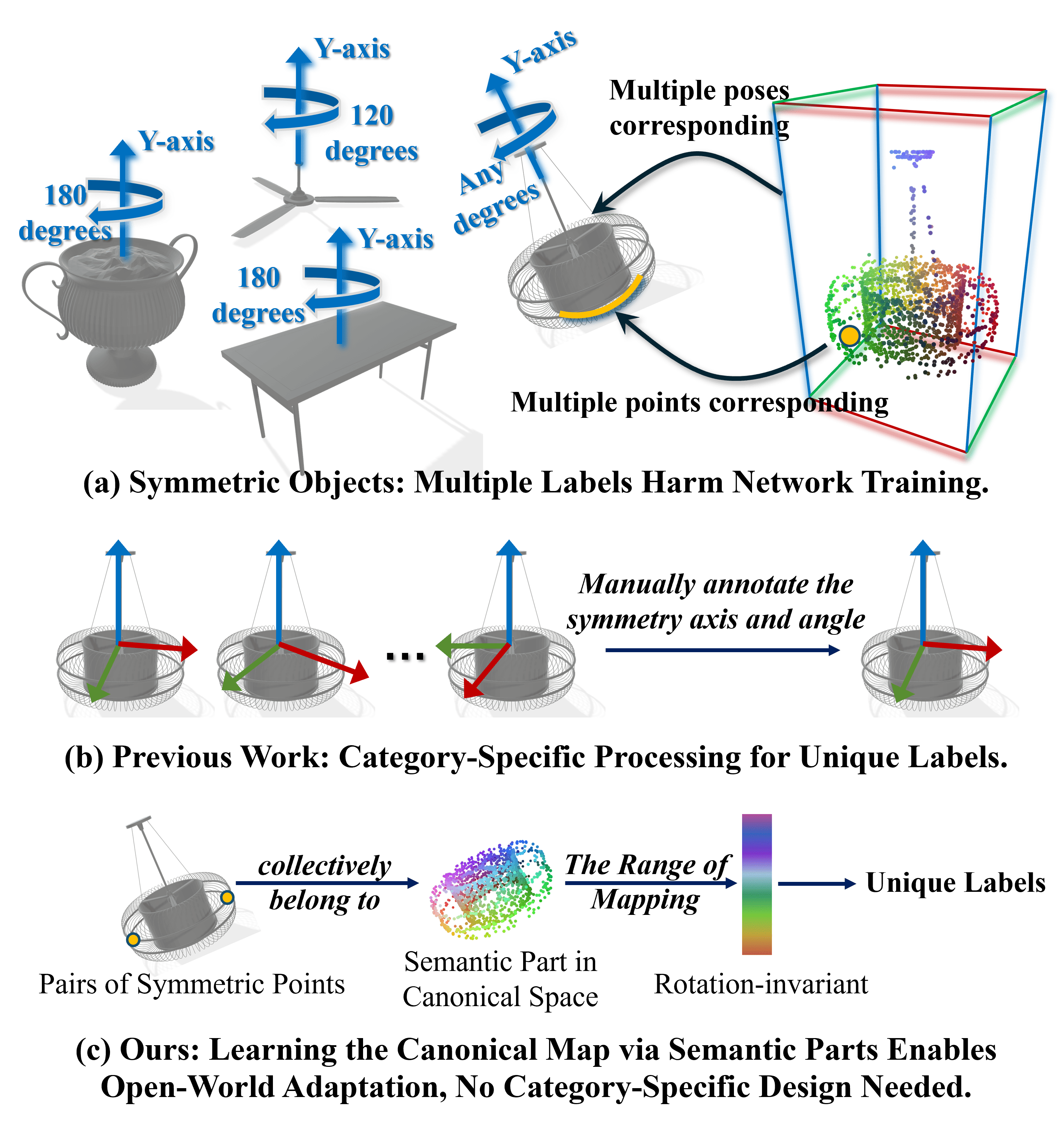
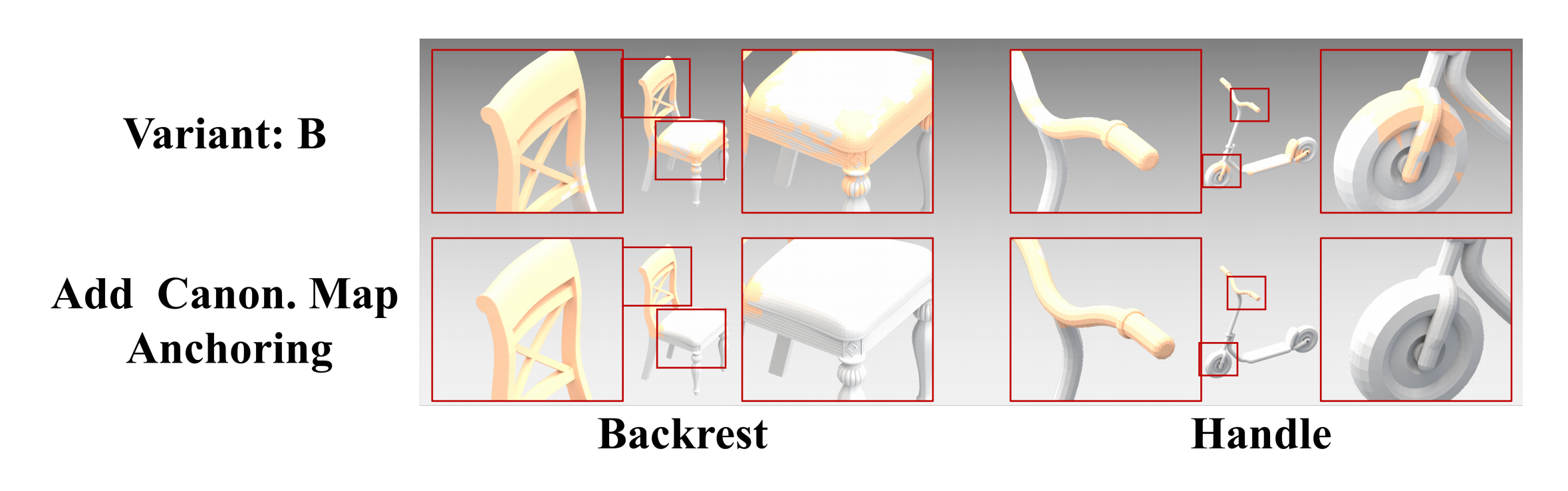
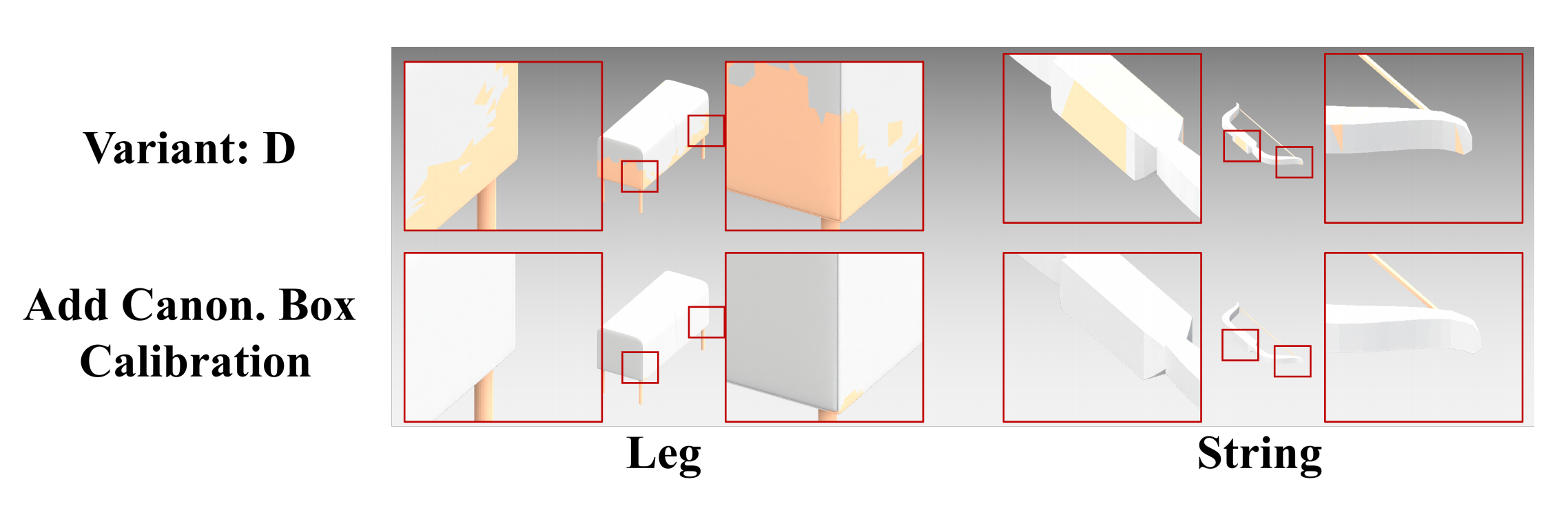
Task. Open-world promptable 3D semantic part segmentation: given a natural language query such as "chair leg" or "door handle", the model segments the target part directly on 3D geometry. CoSMo3D addresses this task by learning to reason in a canonical space rather than raw input pose space.